Introduction to Data Science¶
1MS041, 2023¶
©2023 Raazesh Sainudiin, Benny Avelin. Attribution 4.0 International (CC BY 4.0)
Singular value decomposition¶
In the book they explain the Singular Value Decomposition differently. The concept of singular value decomposition is tightly connected to Principal Component Analysis, and the methods to compute the SVD is how we get the components in PCA. We will therefore switch between explaining tthe ideas in the context of PCA as well as using the linear algebra "geometric" concepts. So, for those of you who know PCA but not SVD will have a hook, but also those of you who know linear algebra will understand the ideas of PCA.
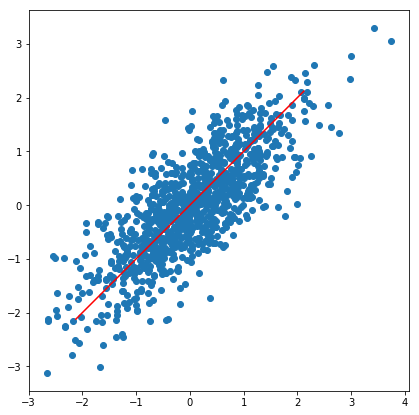
Consider a set of points in $R^d$, for instance the following plot (in $R^2$):
import numpy as np
X = np.random.multivariate_normal(mean=(0,0),cov=[(1,0.8),(0.8,1)],size=(1000,))
def points(X,Y=None):
import matplotlib.pyplot as plt
if (type(Y)!=type(None)):
plt.scatter(X,Y)
else:
if (X.shape[1] == 2):
plt.scatter(X[:,0],X[:,1])
elif ((X.shape[1] != 2) and (X.shape[0] == 2)):
plt.scatter(X[0,:],X[1,:])
points(X)

When we considered linear regression we considered linear approximations and minimized the squared error to find our function. That is, we only considered the y-component of our error.
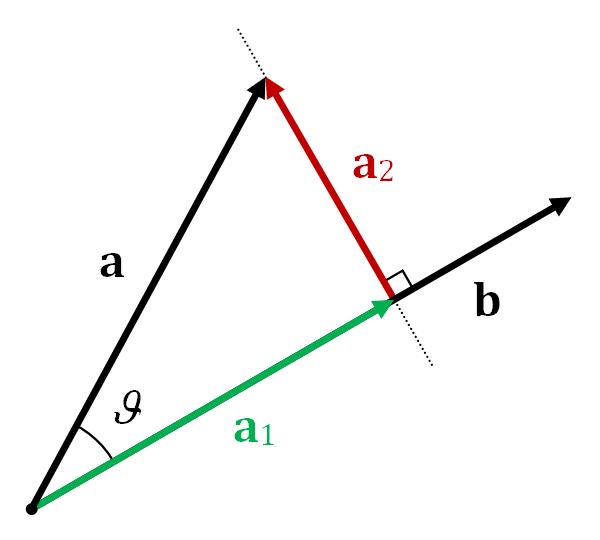
Lets say that we wish to approximate the data using a low-dimensional subspace, think of a low-dimensional hyperplane. In the case of 2d there is only 1d hyperplanes (lines), but if you have, say 100 dimensional we could consider the best fitting 10 dimensional hyperplane. What we mean with best fitting is that the distance from the point to its projection onto our subspace is as small as possible. Think of our 2d example above, then we would like to find the line such that orthogonal projection gives the smallest error. Just looking at the plot we would take the line $y=x$.
But how do we formulate this rigorously?
Consider a line given by the unit vector $v$, and consider a point $x$ then the projection of $x$ onto $v$ is as above given by $$ (v \cdot x) v $$
We will now use these ideas applied to IID samples of points $\{X_1,\ldots,X_n\}\in \mathbb{R}^m$ with zero expectation. Let $w$ be a unit vector. Consider the projection of each $X_i$ onto $v$ but only consider the proportion i.e. $X_i \cdot v$, then define $$ Y_i = (X_i \cdot v) $$ The line with maximal empirical variance can be written as $$ v_1:=\arg\max_{\|v\|=1} \frac{1}{n} \sum_i (Y_i - \overline{Y}_n)^2 = \arg\max_{\|v\|=1} \frac{1}{n} \sum_{j=1}^n ((X_i \cdot v) - \overline{X \cdot v}_n)^2 = \arg\max_{\|v\|=1} \sum_{j=1}^n |X_i \cdot v|^2 $$
If we construct a matrix $A$ of size $n \times m$ with rows $X_i$ then we can rewrite $$ \sum_{j=1}^n |X_i \cdot v|^2 = |Av|^2 $$ and our problem reduces to the linear algebra problem of given an $n \times m$ matrix $A$ to find the direction that is most "expanded/least contracted" by $A$, in the following sense $$ \arg\max_{\|w\|=1} |Av| $$
Note, the singular vectors are not necessarily unique, in fact if $v$ is a singular vector, then so is $-v$. We can also have ties, in that case we arbitrarily pick one. In the following we will as in the book assume that the singular vectors can be picked uniquely, for instance by requiring no ties and that we fix the sign as to make the vector unique.
Definition¶
The vector $v_1 \in \mathbb{R}^m$ of the ($n \times m$) matrix $A$, defined as $$v_1:= \arg\max_{\|v\|=1} |Av|$$ is called the
first singular vectorof $A$. The value $\sigma_1(A)$ defined as $$\sigma_1(A) := |Av_1|$$ is called thefirst singular valueof $A$.
Note¶
In the context where $A$ is constructed from our IID vectors $X_1,\ldots,X_n$, we see that $\sigma_1$ is the standard deviation in the direction of the first singular vector.
Now that we have defined the first singular vector, we can define the second singular vector. This is simply a vector that is orthogonal to $v_1$ again solving our maximum problem, i.e. $$ v_2 := \arg\max_{\|v\|=1, v \perp v_1} |Av| $$
We can interpret this as follows, consider the plane given by the first singular vector $v_1$ as the normal, then we can consider our new problem by finding the vector $v$ that maximizes $|(P_1A)v|$ where $P_1A=\{P_1A_{1,\cdot},\ldots,P_1A_{n,\cdot}\}$ where $P$ is the projection of a vector onto the plane $v_1 \cdot x = 0$.
Theorem (Greedy Algorithm)¶
Let $A$ be an n x d matrix with singular vectors $v_1,...,v_r$. For $1 \leq k \leq r$, let $V_k$ be the subspace spanned by $v_1,\ldots,v_k$. For each $k$, $V_k$ is the best fit $k$-dimensional subspace for $A$.
What is $V_k$? $$ V_k = \{\alpha_1 v_1 + \ldots + \alpha_k v_k: (\alpha_1,\ldots,\alpha_k) \in \mathbb{R}^k\} =: span(\{v_1,\ldots,v_k\}). $$ What do we mean by best fit? Let $\tilde V_k$ be another $k$-dimensional subspace consider the distance of a point $p$ to the $k$-dimensional subspace $\tilde V_k$, such a space is spanned by an orthonormal basis $\tilde v_1, \ldots, \tilde v_k$, the distance from $p$ to $\tilde V_k$ can be seen to be $$ \|p - proj_{\tilde V_k} p\| = \|p - \sum_{i=1}^k (\tilde v_i \cdot p)\tilde v_i\| $$ We mean that $V_k$ is the $k$-dimensional subspace that minimizes $$ \sum_{i=1}^n \|X_i - proj_{\tilde V_k} X_i\|^2 $$
But we can use the Pythagorean theorem to get $$ \sum_{i=1}^n \left (\|proj_{\tilde V_k}X_i\|^2 + \|X_i - proj_{\tilde V_k}X_i\|^2 \right ) = \sum_{i=1}^n \|X_i\|^2 $$
and thus we can get $$ \sum_{i=1}^n \left (\|proj_{\tilde V_k}X_i\|^2 - \|X_i\|^2 \right ) = \sum_{i=1}^n \|X_i - proj_{\tilde V_k}X_i\|^2 $$
From the above we see that the best fitting subspace is the subspace that maximizes the "variance" in the sense that we have seen. The point I am making is that we can rephrase the theorem as saying that finding $v_1,\ldots,v_k$ in a greedy way by maximizing the variance is the same as directly minimizing the variance of the deviation from the subspace.
import numpy as np
from scipy.optimize import minimize
def findFirstSingularVector(A):
'''Takes a matrix of form n x m and returns a tuple of the singular vector and singular value
'''
def negsumofsquares(v):
return -np.sum((A@v)**2)
constraints = ({'type': 'eq', 'fun': lambda w: 1-(np.sum(w**2))})
m = A.shape[1]
random_v = np.random.normal(size=m)
initial_vector=random_v/np.linalg.norm(random_v)
ans1 = minimize(negsumofsquares, x0=initial_vector,constraints=constraints)
if (ans1.success):
return ans1.x,np.sqrt(-ans1.fun)
else:
raise Exception("No convergence")
def projectOnPlane(A,normal):
'''Project the rows of A onto the plane given by "normal * x = 0"'''
return A - (A@normal).reshape(-1,1)*normal
We can now use the code above to find the singular vectors, let us take a look at the example data I plotted above
X.shape
v1,s1 = findFirstSingularVector(X)
print(v1,s1)
import numpy as np
np.linalg.norm(v1)
np.sqrt(1-0.95**2)
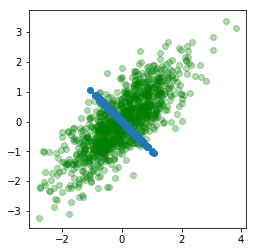
As we can see this is pretty much identical to the vector in the 45 degree direction. To find the second singular vector, we simply project our data onto the plane spanned by having $v_1$ as the normal.
P_1A = projectOnPlane(X,v1)
points(P_1A)

v_2,s2 = findFirstSingularVector(P_1A)
print(v_2,s2)
Its clear which direction this is headed. Let us also look at what happens when we project the data onto the plane with normal $v_2$.
import matplotlib.pyplot as plt
points(projectOnPlane(P_1A,v_2))
plt.xlim(-1,1)
plt.ylim(-1,1)

X.shape
U,D,VT = np.linalg.svd(X,full_matrices=False)
U.shape
D.shape
VT.shape
U.shape
VT.shape
D = np.diag(D)
np.linalg.norm(X-U@D@VT)
Question: What have we done, two projections in a row? What is the projection of a projection?
It should be clear from the definition and the "Greedy Algorithm" theorem that $proj_{V_m} A = A$. That is, if we use all possible singular vectors, then we can represent the data from $A$ as points in $V_m$. That is any row of $A$ can be written as a linear combination of all the singular vectors.
We can now implement findSingularVectors using our methods above
def findSingularVectors(A,k=1):
'''Takes a n x m matrix of points, where the points are on the rows.
It then computes the first k singular vectors with corresponding singular values'''
assert(len(A.shape) == 2), "A needs to be a 2d matrix"
assert((1 <= k) and (k <= A.shape[1])), "We can only compute the number of singular vectors up to the dimension of the data"
vectors = []
values = []
PA = A
for i in range(k):
v,s = findFirstSingularVector(PA)
PA = projectOnPlane(PA,v)
vectors.append(v)
values.append(s)
return vectors,values
findSingularVectors on X is a simple as
findSingularVectors(X,2)
#We can even do 3 dimension
Z = np.random.normal(size=(1000,3))
findSingularVectors(Z,3)
Question: Is this a good way of finding the singular vectors?
YouTry:
Test and see what happens if we try to apply our findSingularValues on something with more dimensions, like 10 dimension and we would like 5 singular vectors, what happens? Why?
Singular Value Decomposition of a Matrix¶
Remember that we said that if we compute $m$ singular vectors of the $n \times m$ dimensional matrix $A$, then $$ proj_{V_m} A = A $$ this implies that we can write each row in $A$ as $X_i = \sum_{j=1}^m (X_i \cdot v_j) v_j$ which we can now rewrite as $$ A = \sum_{j=1}^m A v_j v_j^T $$ denoting $u_i:=\frac{A v_i}{\sigma_i}$ we see that the above expression becomes $$ A = \sum_{j=1}^m \sigma_j u_j v_j^T $$
This is the singular value decomposition. I.e. we have decomposed $A$ into a sum of matrices, that is $u_j v_j^T$ is $n \times m$ matrices.
Rewriting the above equation in matrix format we get $$ A = UDV^T $$ where $U$ is the matrix with $u_1,\ldots$ as the columns, $D$ is a diagonal matrix with $\sigma_i$ as the diagonal and $V$ is the matrix with $v_i$ as columns of $V$.
Definition
The vectors $u_i$ are called the
left singular vectors.
TestQuestion¶
Why does findSingularVectors give rise to no-convergence sometimes, specially when we try to extract many singular vectors, say trying to extract 6 singular vectors from 10-d gaussian random vectors?
Power method¶
Now let us consider the matrix $A^TA$ this matrix has dimension $m \times m$, using our decomposition above we obtain that $$ A^T A = (UDV^T)^T(UDV^T) = (VDU^T UDV^T) = VD^2V^T $$ since $U^TU = I$ which comes from the fact that the columns are orthonormal. This means that for any column $v_i$ in $V$ $$ A^T A v_i = VD^2V^T v_i = \sigma_i^2 v_i $$ so we see that $v_i$ is the $i$:th eigenvector of $A^T A$ with eigenvalue $\sigma_i^2$. We can thus find the singular vectors by trying to find the eigenvectors of $A^T A$.
How do we find the eigenvectors of $B = A^T A$? Well first note that $$ B^k = (V D^2 V^T)^k = (V D^{2k} V^T) $$ by the same argument as above, i.e. $V^T V = I$. Thus we see that if $\sigma_1 > \sigma_2$ then if we let $k$ be large enough then $$ B^k \approx (\sigma_1)^{2k} v_1 v_1^T. $$
Z1 = np.random.normal(size=(1000,10))
Z1 = Z1-np.mean(Z1,axis=0).reshape(1,-1)
B=Z1.T@Z1
print(B.shape)
B_0 = B
v1_approx = B[:,0]
for i in range(200):
B_0 = B@B_0
B_0 = B_0 / np.linalg.norm(B_0) # Just normalize so that we reduce change of overflow
# Take the first column of B_0
b = B_0[:,0]
v1_approx = b/np.linalg.norm(b)
Let us check what result we got
v1_approx
The vector we get is supposed to be an eigenvector of $B$, let us check if that is true
Bv1 = B@v1_approx
v1_approx-Bv1/np.linalg.norm(Bv1)
Ok, so most components are of order $10^{-7}$, which is fairly accurate. Let us check with numpy's built in SVD and see what we get
U,D,VT = np.linalg.svd(Z1,full_matrices=False) # Interestingly enough numpy documentation calls this reduced SVD
SVD from numpy returns $U,D,V.T$ so that we can write Z1 = U@np.diag(D)@V.T. Remember that the columns of $V$ is the singular vectors, so we can extract them as follows
V = VT.T
V[:,0]
We can also check if we get back our original matrix $Z1$ if we multiply everything together
# square error is of the order $10^{-13}$, pretty good
np.linalg.norm(Z1-(U@np.diag(D)@VT))
TestQuestion¶
Use the power method to compute the first 5 singular vectors for the matrix problem5_Z found below. Compute each singular vector to the tolerance of $10^{-6}$, in the following sense, (call $Z=$ problem5_Z)
$$
\left \| v - \frac{Z^T Z v}{\|Z^T Z v\|} \right \| < 10^{-6}.
$$
for the proposed singular unit vector $v$.
import numpy as np
problem5_Z = np.array([[ 1.21395528, 0.61319117, 0.96775704, 0.47560786, 0.46944868,
-0.96174286, -0.04597716, 1.11423879, -2.16790516, 1.41559609],
[-1.74579582, -2.96579703, -1.53883473, -2.08891653, -2.51835633,
0.28005013, 3.14477698, 0.27859531, -0.21063502, 1.21238791],
[-1.38846711, -2.36561478, 2.00400938, -0.81219207, 0.76351148,
-0.94135869, 1.81624568, 0.30603084, 0.4502897 , -1.68275369],
[-0.83770176, -1.12651679, 0.72947716, 0.28293936, -1.54650026,
1.47451872, 0.58828722, 2.63367002, -1.75123164, 0.20599531],
[ 0.16922431, 0.07605318, 0.87850331, 0.45439765, -0.36589416,
-1.16866643, 1.00148338, -2.24790302, -1.03375691, 0.66441057],
[ 0.18417791, -0.6944261 , 0.11811434, -0.02291727, -3.49209616,
2.567174 , -0.79506183, -0.61917615, -0.25294073, -0.44972644],
[ 0.21973089, 0.58409936, 0.05358338, 0.09448722, 1.18545664,
0.09458799, -1.45002309, 1.38528763, -0.26669331, -0.02398977],
[-0.77246978, -1.29899321, 0.32673874, 0.41253631, 0.9496008 ,
0.23276985, -0.44480295, -1.70329931, 0.74889995, 0.10723953],
[ 0.87892498, 1.51055297, 0.99208142, 0.15116986, -0.419831 ,
-1.51231948, 2.44759401, -0.34096878, 0.78995641, 0.1464366 ],
[ 0.4855678 , -0.49584481, 0.97413157, -1.44802482, 0.4773462 ,
0.08619087, -1.15799392, -0.3331743 , -1.40555249, -0.76420582]])
# replace XXX with the computed singular vectors put together in a numpy array of the shape
# (5,10). So each row is a singular vector and ordered in decending order:
# first singular vector on first row etc.
first_five_singular_vectors = XXX
# Testcell
local_points=0
try:
import numpy as np
problem5_answer=np.array([[ 0.32065325, 0.53900444, 0.09356045, 0.25556044, 0.52719521,
-0.20401069, -0.45327304, -0.07215404, 0.03412725, -0.03476398],
[ 0.098965 , 0.07623664, -0.16995098, 0.08072382, -0.3485694 ,
0.57549099, -0.56745898, 0.33191372, -0.2513528 , 0.03080728],
[ 0.06708422, 0.02228414, 0.29541748, -0.01999769, 0.14763549,
-0.23413362, 0.23929551, 0.70627663, -0.50364261, 0.14481729],
[ 0.32496783, 0.48773113, -0.17988031, 0.16765514, -0.49023105,
-0.12218743, 0.34029333, -0.17990397, -0.10206726, 0.42686077],
[ 0.16666869, -0.15579472, 0.63618711, 0.02305179, -0.20672361,
0.02040642, -0.11854824, -0.4919846 , -0.47101739, -0.14687796]])
assert (type(first_five_singular_vectors) == np.ndarray)
assert (first_five_singular_vectors.shape == (5,10))
for i in range(5):
if ((np.linalg.norm(first_five_singular_vectors[i,:]-problem5_answer[i,:]) < 10^(-4))
and np.linalg.norm(first_five_singular_vectors[i,:]-problem5_answer[i,:]) > 10^(-7)):
local_points+=RR(3/5)
else:
print("Singular vector %d incorrect" % (i+1))
print("Its either wrong or you did cheat! Dont use numpy.svd write your own code! Remember compute to precision 10^(-6)")
except Exception as e:
print(e)
print("You have failed to pass the test. Try again...")
else:
print("You have passed the test for this problem, congratulations!")
finally:
local_points = int(local_points)
print("The number of points you have scored for this problem so far = "+str(local_points))
PCA¶
What is PCA, well basically it is a coordinate transformation from the original coordinates to the coordinate system given by the singular vectors. Since $V$ is orthonormal it is as simple as a product, i.e.
$$ A = UDV^T $$Recall that each row in $A$ is a data point i.e. an $m$ dimensional vector and that $V$ is an orthonormal basis, as such we project each point in $A$ onto each basis vector from $V$ by using dot products, as in $(X_i \cdot v_i)v_i$, the coordinate in the basis is just $X_i \cdot v_i$, and as such we get $$ PCA(A) = AV = UDV^TV = UD $$ Lets try it out
U@np.diag(D)
(Z1@V)@V.T
PCA class¶
since we dont all have sklearn lets implement our own PCA class that we can use from now.
import numpy as np
class PCA(object):
def __init__(self,n_components):
self.n_components = n_components
self.components=None
self.singular_values=None
self.dimension=None
self.mean=None
def fit(self,X):
assert(type(X) == np.ndarray), "Please input type np.ndarray!"
assert(len(X.shape) == 2), "Please input 2d array!"
assert(min(X.shape[1],X.shape[0]) >= self.n_components), "min(X.shape[1],X.shape[0]) >= self.n_components!"
print("Number of data_points: %d, number of features: %d, Number of components: %d" %(X.shape[0],X.shape[1],self.n_components))
X = self._center(X) # Make sure the data is centered (each feature has empirical mean zero)
self.dimension=X.shape[1] # This is the dimension of the data
self.components,self.singular_values = self._compute(X) # Compute the singular vectors
def _center(self,X):
self.mean = np.mean(X,axis=0).reshape(1,-1)
return X-self.mean
def transform(self,X):
if (type(self.components) == None):
raise Exception("Not fitted yet!")
assert(type(X) == np.ndarray), "Please input type np.ndarray!"
assert(len(X.shape) == 2), "Please input 2d array!"
assert(X.shape[1] == self.dimension), "Incorrect number of features!"
return (X-self.mean)@self.components
def inverse_transform(self,X):
if (type(self.components) == None):
raise Exception("Not fitted yet!")
assert(type(X) == np.ndarray), "Please input type np.ndarray!"
assert(len(X.shape) == 2), "Please input 2d array!"
assert(X.shape[1] == self.n_components), "Incorrect number of features!"
return X@self.components.T+self.mean
def project(self,X):
return self.inverse_transform(self.transform(X))
def _compute(self,X):
U,D,VT = np.linalg.svd(X,full_matrices=False)
return (VT.T)[:,:self.n_components],D
def get_components(self):
return self.components
def get_dimension(self):
return self.dimension
pca = PCA(2)
pca.fit(Z1)
SVD in Action¶
This is all cool and such, but what can you do with it?
Singular value decomposition can be used in the following ways
Factor Analysis¶
- Studying underlying factors. The famous
g factor: proposed by Spearman (Spearman correlation), to describe "general intelligence" as a singular vector based on data about IQ, Math ability and other cognitive tests. This is also called Factor analysis.
def showURL(url, ht=500):
"""Return an IFrame of the url to show in notebook with height ht"""
from IPython.display import IFrame
return IFrame(url, width='95%', height=ht)
showURL('https://en.wikipedia.org/wiki/G_factor_(psychometrics)#Factor_structure_of_cognitive_abilities',300)
showURL('https://en.wikipedia.org/wiki/Principal_component_analysis#Applications')
- Compressing a representation of data, as a dimensional reduction technique. This is similar to the rank $k$ approximation idea.
Example on compressing data¶
def load_digits():
import csv
data = []
target = []
with open('data/digits.csv', mode='r') as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
data.append([float(x) for x in row[:-1]])
target.append(int(row[-1]))
return np.array(data),np.array(target)
X,Y = load_digits()
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2,5)
plt.gray()
for i in range(10):
row = i//5
column = i % 5
ax[row,column].imshow(X[i,:].reshape(8,8))

pca_digit = PCA(10)
pca_digit.fit(X)
X.shape
pca = PCA(n_components=10)
pca.fit(X)
X_projected = pca.inverse_transform(pca.transform(X))
fig, ax = plt.subplots(2,5)
plt.gray()
for i in range(10):
row = i//5
column = i % 5
ax[row,column].imshow(X_projected[i,:].reshape(8,8))

A= np.array([[0,0,0,1,1,0,0,0],
[0,0,1,1,1,1,0,0],
[0,1,0,0,0,0,1,0],
[1,1,0,0,0,0,1,1],
[1,1,1,1,1,1,1,1],
[1,1,1,1,1,1,1,1],
[1,1,0,0,0,0,1,1],
[1,1,0,0,0,0,1,1]])
A_proj = pca.inverse_transform(pca.transform(A.reshape(1,-1)))
plt.imshow(A_proj.reshape(8,8))

Explained variance¶
Explained variance is how much percentage of the total variance is captured by our singular vectors. Remember the interpretation of the singular values as the standard deviation, as such the variance explained of the first $k$ components is just the sum of the singular values squared and divided by the total variance.
variances = pca_digit.singular_values**2/(X.shape[0]-1)
np.cumsum(variances/np.sum(variances))
Decorrelation¶
Note that since the singular vectors are orthogonal, we immediately have that the transformed values always have zero correlation.
Another example on compressing data, building a classifier¶
import csv
features = []
labels = []
with open('data/leukemia.csv',mode='r') as f:
reader = csv.reader(f)
header=next(f)
for row in reader:
features.append(np.array(row[:-1],dtype=float))
labels.append((row[-1] == 'ALL')*1)
X = np.stack(features,axis=0)
Y = np.array(labels)
# https://github.com/mavaladezt/kNN-from-Scratch
def knn_distances(xTrain,xTest,k):
"""
Finds the k nearest neighbors of xTest in xTrain.
Input:
xTrain = n x d matrix. n=rows and d=features
xTest = m x d matrix. m=rows and d=features (same amount of features as xTrain)
k = number of nearest neighbors to be found
Output:
dists = distances between all xTrain and all XTest points. Size of n x m
indices = k x m matrix with the indices of the yTrain labels that represent the point
"""
#the following formula calculates the Euclidean distances.
import numpy as np
distances = -2 * xTrain@xTest.T + np.sum(xTest**2,axis=1) + np.sum(xTrain**2,axis=1)[:, np.newaxis]
#because of float precision, some small numbers can become negatives. Need to be replace with 0.
distances[distances < 0] = 0
distances = distances**.5
indices = np.argsort(distances, 0) #get indices of sorted items
distances = np.sort(distances,0) #distances sorted in axis 0
#returning the top-k closest distances.
return indices[0:k,:], distances[0:k,:]
def knn_predictions(xTrain,yTrain,xTest=None,k=3):
"""
Uses xTrain and yTrain to predict xTest.
Input:
xTrain = n x d matrix. n=rows and d=features
yTrain = n x 1 array. n=rows with label value
xTest = m x d matrix. m=rows and d=features (same amount of features as xTrain)
k = number of nearest neighbors to be found
Output:
predictions = predicted labels, ie preds(i) is the predicted label of xTest(i,:)
"""
import numpy as np
if (xTest == None):
xTest = xTrain
indices, distances = knn_distances(xTrain,xTest,k)
yTrain = yTrain.flatten()
rows, columns = indices.shape
predictions = list()
for j in range(columns):
temp = list()
for i in range(rows):
cell = indices[i][j]
temp.append(yTrain[cell])
predictions.append(max(temp,key=temp.count)) #this is the key function, brings the mode value
predictions=np.array(predictions)
return predictions
def score(prediction,true_values):
return np.sum(prediction == true_values)/len(prediction)
score(knn_predictions(X,Y,k=5),Y)
k = 2
pca_leukemia = PCA(n_components=k)
pca_leukemia.fit(X)
X_leukemia_project = pca_leukemia.transform(X)
score(knn_predictions(X_leukemia_project,Y,k=5),Y)
def standardScaler(X_in):
'''Takes an array of shape (n_samples,n_features) and centers and normalizes the data'''
X_out = (X_in-np.mean(X_in,axis=0))/np.std(X_in,axis=0)
return X_out
if (k in [2,3]):
X_leukemia_project_rescale = standardScaler(X_leukemia_project)
class0 = X_leukemia_project_rescale[Y==0]
class1 = X_leukemia_project_rescale[Y==1]
plt.scatter(class0[:,0],class0[:,1],color='blue')
plt.scatter(class1[:,0],class1[:,1],color='red')
# P=points(class0,color='blue',size=20)
# P+=points(class1,color='red',size=20)
# P.show()
From the above plot, it should be possible to use logistic regression to solve this problem
pca_leukemia_2d = PCA(n_components=2)
pca_leukemia_2d.fit(X)
X_leukemia_project_2d = standardScaler(pca_leukemia_2d.transform(X))
Cool, lets do logistic regression
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_leukemia_project_2d,Y)
lr.score(X_leukemia_project_2d,Y)
Comments¶
You would think that since both PCA and Logistic regression are linear that PCA+LogisticRegression would be the same as just LogisticRegression in the first place. This is not true, as PCA and LogisticRegression are minimizing different things, remember, for instance, the way we measure error (vertical / orthogonal).
We can also illustrate it here.
# Lets try to map it to 2d
pca1 = PCA(n_components=2)
pca1.fit(X)
lr1 = LogisticRegression()
lr1.fit(standardScaler(pca1.transform(X)),Y)
lr1.score(standardScaler(pca1.transform(X)),Y)
# Lets try to map it to 5d
pca2 = PCA(n_components=5)
pca2.fit(X)
lr2 = LogisticRegression()
lr2.fit(standardScaler(pca2.transform(X)),Y)
lr2.score(standardScaler(pca2.transform(X)),Y)
# Lets try to map it to 10d
pca3 = PCA(n_components=10)
pca3.fit(X)
lr3 = LogisticRegression()
lr3.fit(standardScaler(pca3.transform(X)),Y)
lr3.score(standardScaler(pca3.transform(X)),Y)
Intriguing, so we see that it is something else. Perhaps, at this point you might also remember that PCA does not use the labels, it just represents the data $X$ in different coordinates.
Recommender engines¶
Let us say that we have a library of movies, lets say that we have $m$ movies. Furthermore assume that we have $n$ users that are watching these movies and outputting a like whenever they liked a movie. We can represent this as a matrix of the form $n \times m$, with a $1$ in position $i,j$ if user $i$ liked movie $j$.
There is an idea that is called collaborative filtering:
showURL('https://en.wikipedia.org/wiki/Collaborative_filtering')
showURL('https://en.wikipedia.org/wiki/Matrix_factorization_(recommender_systems)',500)
Note that we can from the singular value decomposition and what we did with PCA we can do the following
$$ A = U \Sigma V^T = \begin{bmatrix} U_1 & U_2 \end{bmatrix} \begin{bmatrix} \Sigma_r & 0 \\ 0 & 0 \end{bmatrix} \begin{bmatrix} V_1^T \\ V_2^T \end{bmatrix} = U_1 \left(\Sigma_r V_1^T\right) . $$This method is a type of ranking factorization, note that for $C = U_1$ and $F = \Sigma_r V_1^T$, then the product $CF$ is a low rank factorization approximation of $A$.
import csv
user_item_data=[]
with open('data/ratings.csv',mode='r') as f:
reader = csv.reader(f)
print(next(reader))
for row in reader:
user_item_data.append(row)
movie_ids = [row[1] for row in user_item_data]
users = [row[0] for row in user_item_data]
#user_item_data[:10]
n_movies = len(set(movie_ids))
movie_to_index_dict = dict(zip(set(movie_ids),range(n_movies)))
n_users = len(set(users))
user_to_index_dict = dict(zip(set(users),range(n_users)))
user_item = np.zeros((n_users,n_movies))
for row in user_item_data:
user_index = user_to_index_dict[row[0]]
movie_index = movie_to_index_dict[row[1]]
if (float(row[2]) > 3): # Lets say that rating >3 is that user liked it
user_item[user_index,movie_index] = 1
U,D,VT = np.linalg.svd(user_item,full_matrices=False)
Lets choose a small value for the rank, lets say $100$
n_latent = 100
C = U[:,:n_latent]
F = np.diag(D[:n_latent])@VT[:n_latent,:]
C.shape
F.shape
np.sum(np.abs(user_item-(C@F > 1/2)))/np.sum(user_item)
Now the idea is that $CF$ is the prediction of the scores, and we would construct a recommendation for each user based on that which is predicted in $CF$ but the user has not yet seen. We could set a threshold for predicted as $>1/2$ or we could simply list the recommendations in order of descending predicted score.
This is a simple recommender system and this is a fairly large field of study.