Introduction to Data Science¶
1MS041, 2023¶
©2023 Raazesh Sainudiin, Benny Avelin. Attribution 4.0 International (CC BY 4.0)
Markov Chains and Random Structures¶
Markov chain, named after Andrey Markov, is a mathematical model for a possibly dependent sequence of random variables.

Intuitively, a Markov Chain is a system which "jumps" among several states, with the next state depending (probabilistically) only on the current state. A useful heuristic is that of a frog jumping among several lily-pads, where the frog's memory is short enough that it doesn't remember what lily-pad it was last on, and so its next jump can only be influenced by where it is now.
Formally, the Markov property states that the conditional probability distribution for the system at the next step (and in fact at all future steps) given its current state depends only on the current state of the system, and not additionally on the state of the system at previous steps:
$$P(X_{n+1} \ | \, X_1,X_2,\dots,X_n) = P(X_{n+1}|X_n). \,$$Since the system changes randomly, it is generally impossible to predict the exact state of the system in the future. However, the statistical and probailistic properties of the system's future can be predicted. In many applications it is these statistical properties that are important.
Formal definition and terms¶
A Markov chain is a sequence of random variables $X_1, X_2, X_3, \ldots$ with the Markov property, namely that, given the present state, the future and past states are independent. Formally,
$$P(X_{n+1}=x \ | \ X_1=x_1, X_2=x_2 \ldots, X_n=x_n) = P(X_{n+1}=x|X_n=x_n).\,$$The possible values of $X_i$ or the set of all states of the system form a countable set $\mathbb{X}$ called the state space of the chain.
The changes of state of the system are called transitions, and the probabilities associated with various state-changes are called transition probabilities.
Markov chains are often depicted by a weighted directed graph, where the edges are labeled by the probabilities of going from one state to the other states. This is called the flow diagram or transition probability diagram. The transition probability matrix $\mathbf{P}$ encodes the probabilities associated with state-changes or "jumps" from one state to another in the state-space $\mathbb{X}$. If $\mathbb{X}$ is labelled by $\{0,1,2,\ldots\}$ then the $i,j$-th entry in the matrix $\mathbf{P}$ corresponds to the probability of going from state $i$ to state $j$ in one time-step.
$$\mathbf{P} = \begin{bmatrix} p_{0,0} & p_{0,1} & p_{0,2} & \ldots \\ p_{1,0} & p_{1,1} & p_{1,2} & \ldots \\ p_{2,0} & p_{2,1} & p_{2,2} & \ldots \\ \vdots & \vdots & \vdots & \ddots \end{bmatrix}$$The state of the system at the $n$-th time step is described by a state probability vector $$\mathbf{p}^{(n)} = \left( \mathbf{p}^{(n)}_0, \mathbf{p}^{(n)}_1, \mathbf{p}^{(n)}_2,\ldots \right)$$ Thus, $\mathbf{p}^{(n)}_i$ is the probability you will find the Markov chain at state $i \in \mathbb{X}$ at time-step $n$ and $\mathbf{p}^{(0)}_i$ is called the initial probability vector at the convenient initial time $0$.
The state space $\mathbb{X}$ and transition probability matrix $\mathbf{P}$ completely characterizes a Markov chain.
Example 1: Dry-Wet chain, a toy weather model¶
A SageMath break-down of the Wiki Example¶
from Utils import showURL
showURL('https://en.wikipedia.org/wiki/Examples_of_Markov_chains#A_simple_weather_model',400)
We can coarsely describe the weather of a given day by a toy model that states if it is "wet" or "dry". Each day the weather in our toy model is an element of our state space
$$\mathbb{X} = \{\text{"wet"}, \text{"dry"}\}.$$We can make a picture of our toy probability model with a flow diagram or transition probability diagram as follows:
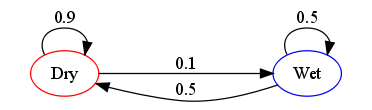
The probabilities of weather conditions, given the weather on the preceding day, can be represented by a transition probability matrix:
$$\mathbf{P} = \begin{bmatrix} 0.9 & 0.1\\ 0.5 & 0.5 \end{bmatrix}$$The matrix $\mathbf{P}$ represents our toy weather model in which a dry day is 90% likely to be followed by another dry day, and a wet or rainy day is 50% likely to be followed by another wet day. The columns can be labelled "dry" and "wet" respectively, and the rows can be labelled in the same manner. For convenience, we will use integer labels $0$ and $1$ for "dry" and "wet", respectively.
$(\mathbf{P})_{i j}=p_{i,j}$ is the probability that, if a given day is of type $i$, it will be followed by a day of type $j$.
Since the transition probability matrix $\mathbf{P}$ is a stochastic matrix:
The rows of $\mathbf{P}$ sum to $1$. The probabiltites in each row can be thought of as "current-state" specific $de~Moivre(p_{i,j}'s)$ distribution Basically, you toss a current-state-specific many-faced weigted die to determine the next state How can we think of our toy weather model in terms of two Bernouli trials; $Bernoulli(0.9)$ and $Bernoulli(0.5)$?
Let's construct and assign the matrix to P.
import numpy as np
P = np.matrix([[9/10,1/10],[1/2,1/2]])
P # display P
P[0,1] # recall accessing (i,j)-th entry of matrix P
Predicting the weather with our Dry-Wet chain¶
The weather on day 0 is known to be dry. This is represented by a probability vector in which the "dry" entry is 100%, and the "wet" entry is 0%:
$$ \mathbf{p}^{(0)} = \begin{bmatrix} 1 & 0 \end{bmatrix} $$The weather on day 1 can be predicted by:
$$ \mathbf{p}^{(1)} = \mathbf{p}^{(0)} \ \mathbf{P} = \begin{bmatrix} 1 & 0 \end{bmatrix} \begin{bmatrix} 0.9 & 0.1 \\ 0.5 & 0.5 \end{bmatrix} = \begin{bmatrix} 0.9 & 0.1 \end{bmatrix} $$Thus, there is an 90% chance that day 1 will also be sunny.
p0 = np.matrix((1,0)) # initial probability vector for a dry day zero
p0
p1 = p0*P # left multiply the matrix by the state prob vector
p1
The weather on day 2 can be predicted in the same way:
$$\mathbf{p}^{(2)} =\mathbf{p}^{(1)} \ \mathbf{P} = \mathbf{p}^{(0)} \ \mathbf{P}^2 = \begin{bmatrix} 1 & 0 \end{bmatrix} \ \begin{bmatrix} 0.9 & 0.1 \\ 0.5 & 0.5 \end{bmatrix}^2 = \begin{bmatrix} 0.86 & 0.14 \end{bmatrix}$$or, equivalently,
$$ \mathbf{p}^{(2)} =\mathbf{p}^{(1)} \ \mathbf{P} = \begin{bmatrix} 0.9 & 0.1 \end{bmatrix} \ \begin{bmatrix} 0.9 & 0.1 \\ 0.5 & 0.5 \end{bmatrix} = \begin{bmatrix} 0.86 & 0.14 \end{bmatrix} $$How do we do this in Sage?
p2 = p0*P**2 # left multiply the initial probability vector by square of P
p2 # disclose the probability vector at time-step 2
or, equivalently,
p2 = p1*P # left multiply the probability vector at time-step 1 by P
# disclose the probability vector at time-step 2 (compare output of previous cell)
p2
General rules for day $n$ follow from mathematical induction as follows:
$$ \mathbf{p}^{(n)} = \mathbf{p}^{(n-1)} \ \mathbf{P} $$$$ \mathbf{p}^{(n)} = \mathbf{p}^{(0)} \ \mathbf{P}^n $$How do we operate with a matrix in SageMath to do this for any given $n$?
n = 3 # assign some specific time-step or day
dry_p0 = np.matrix((1,0)) # initial probability vector for a dry day zero
pn = dry_p0 * P**n # probability vector for day n
pn # display it
n = 3 # assign some specific time-step or day
wet_p0 = np.matrix((0,1)) # initial probability vector for a wet day zero
pn = wet_p0 * P**n # probability vector for day n
pn # display it
Let's get the state probability vector at time n = 0,1,...,nmax
nmax = 3 # maximum number of days or time-steps of interest
[(n, np.matrix((0,1)) * P**n ) for n in range(nmax+1)]
In the next interact let's visualize the $n$-step state probability vector $\mathbf{p}^{(n)}=(\mathbf{p}^{(n)}_0,\mathbf{p}^{(n)}_1)$, $n=0,1,\ldots, {\tt nmax}$ steps
See what's going on here...?
Try to increase nmax and see where the state prob vector is going geometrically.
[np.matrix((1,0)) * P**n for n in range(nmax)]
from ipywidgets import interact, IntSlider
@interact
def nStepProbVec(nmax=IntSlider(1,1,50,1)):
import matplotlib.pyplot as plt
dry_p0 = np.stack([np.matrix((0.2,0.8)) * P**n for n in range(nmax)],axis=0)
plt.scatter(np.array(dry_p0[:,0]),np.array(dry_p0[:,1]),color='red',alpha=0.5)
wet_p0 = np.stack([np.matrix((.6,0.4)) * P**n for n in range(nmax)],axis=0)
plt.scatter(np.array(wet_p0[:,0]),np.array(wet_p0[:,1]),alpha=0.5)
plt.xlabel('dry')
plt.ylabel('wet')
plt.xlim(0,1)
plt.ylim(0,1)
Steady state of the weather in our Dry-Wet chain¶
In this example, predictions for the weather on more distant days are increasingly inaccurate and tend towards a steady state vector. This vector represents the probabilities of dry and wet weather on all days, and is independent of the initial weather.
The steady state vector is defined as:
$$\mathbf{s} = \lim_{n \to \infty} \mathbf{p}^{(n)}$$but only converges to a strictly positive vector if $\mathbf{P}$ is a regular transition matrix (that is, there is at least one $\mathbf{P}^n$ with all non-zero entries making the Markov chain irreducible and aperiodic).
Since the $\mathbf{s}$ is independent from initial conditions, it must be unchanged when transformed by $\mathbf{P}$. This makes it an eigenvector (with eigenvalue $1$), and means it can be derived from $\mathbf{P}$. For our toy model of weather:
$$\begin{matrix} \mathbf{P} & = & \begin{bmatrix} 0.9 & 0.1 \\ 0.5 & 0.5 \end{bmatrix} \\ \mathbf{s} \ \mathbf{P} & = & \mathbf{s} & \mbox{(} \mathbf{s} \mbox{ is unchanged by } \mathbf{P} \mbox{.)} \\ & = & \mathbf{s} \ \mathbf{I} \\ \mathbf{s} \ (\mathbf{P} - \mathbf{I}) & = & \mathbf{0} \\ & = & \mathbf{s} \left( \begin{bmatrix} 0.9 & 0.1 \\ 0.5 & 0.5 \end{bmatrix} - \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} \right) \\ & = & \mathbf{s} \begin{bmatrix} -0.1 & 0.1 \\ 0.5 & -0.5 \end{bmatrix} \end{matrix}$$$$\begin{bmatrix} \mathbf{s}_0 & \mathbf{s}_1 \end{bmatrix} \begin{bmatrix} -0.1 & 0.1 \\ 0.5 & -0.5 \end{bmatrix} = \begin{bmatrix} 0 & 0 \end{bmatrix}$$
So $- 0.1 \mathbf{s}_0 + 0.5 \mathbf{s}_1 = 0$ and since they are a probability vector we know that $\mathbf{s}_0 + \mathbf{s}_1 = 1$.
Solving this pair of simultaneous equations gives the steady state distribution:
$$\left( \mathbf{s}_0 , \mathbf{s}_1 \right) = \left( 5/6 , 1/6 \right) = \left( 0.833 , 0.167 \right)$$In conclusion, in the long term, 83% of days are dry.
How do we operate the above to solve for $\mathbf{s}$ in Python? There are two "methods". We can either use
- Method 1: solve a system of linear equations with
sympyto get $\mathbf{s}$ or - Method 2: obtain $\mathbf{s}$ via eigen decomposition.
Method 1: You Try¶
Method 2:¶
Alternatively use eigen decomposition to solve for $\mathbb{s}$.
If your linear algebra is rusty¶
To follow Method 2 you need to know a bit more about eigen values, eigen vectors and eigen spaces.
Learn from Khan academy more slowly: -https://www.khanacademy.org/math/linear-algebra/alternate-bases/eigen-everything/v/linear-algebra-introduction-to-eigenvalues-and-eigenvectors
Also, ensure you really understand the visual interactive exploration of low-dimensional eigen values and eigen vectors here:
Using numpy linalg to compute the eigenvalues and eigenvectors. It returns a tuple, the first is the array of the eigenvalues and the second is a matrix of eigenvectors. From the above, we see that the one we are after is the eigenvector corresponding to the eigenvalue $1$.
evals,evecs = np.linalg.eig(P.T)
evals,evecs
The eigenvectors are columns of the evecs matrix, and it is the first we are interested in. This will have norm $1$, but we need to make sure that the sum is $1$, so that it is a probability mass function. See
first_evec = evecs[:,0]
np.array(first_evec) / np.sum(first_evec)
Working with real data¶
import numpy as np
chcRainfallData = np.genfromtxt('data/rainfallInChristchurch.csv', delimiter=",")
## Yeah, this is a much easier way to read a csv file into numpy array!
## But this data was preformatted with no errors during type conversion
len(chcRainfallData)
chcRainfallData[0:10]
chcRainfallData[-1] # the data goes from 1943 August 02 to 2012 May 06
from ipywidgets import interact, IntSlider
@interact
def chch_precipitation(start_date = IntSlider(0,0,len(chcRainfallData)-100,1), end_date = IntSlider(0,10,len(chcRainfallData)-1,1)):
sel_data = chcRainfallData[start_date:end_date]
sel_daysdata = np.array([[i,sel_data[i][1]] for i in range(len(sel_data))])
import matplotlib.pyplot as plt
plt.scatter(sel_daysdata[:,0],sel_daysdata[:,1])
plt.xlabel('days')
plt.ylabel('mm')
all_daysdata = (chcRainfallData[:,1] > 0)*1
all_daysdata[200:210]
np.mean(all_daysdata)
Interactive cell to allow you to select some specific data and turn it into the list of 0 or 1 tuples (this list will then be available in sel_daysdata in later cells in the worksheet).
Daily Precipitation at Christchurch, fed from NIWA data (NZ's equivalent of US's NOAA)¶
@interact
def chch_wetdry(start_date = IntSlider(0,0,len(chcRainfallData)-100,1), end_date = IntSlider(0,10,len(chcRainfallData)-1,1)):
#global all_daysdata # made it a global so it is easy to choose data
sel_data = all_daysdata[start_date:end_date]
import matplotlib.pyplot as plt
plt.scatter(range(end_date-start_date),sel_data)
plt.xlabel('days')
plt.ylabel('Dry/Wet')
Maximum likelihood estimation of the unknown transition probabilities¶
for the Dry-Wet Markov chain model of Christchurch weather¶
In the example we have been working with earlier, the transition probabilities were given by the matrix $$\mathbf{P}=\begin{bmatrix} 0.9 & 0.1\\0.5&0.5\end{bmatrix}$$ and we simply used the given $\mathbf{P}$ to understand the properties and utilities of the probability model for a possibly dependent sequence of $\{0,1\}$-valued random variables encoding the $\{\text{Dry},\text{Wet}\}$ days, respectively.
What we want to do now is use the data from Christchurch's Aeroclub obtained from NIWA to estimate Christchurch's unknown transition probability matrix $$\mathbf{P}= \begin{bmatrix} p_{0,0} & p_{0,1}\\ p_{1,0} & p_{1,1} \end{bmatrix}.$$
Minimizing the empirical log loss we get
$$\widehat{p}_{0,0} = \frac{n_{0,0}}{n_{0,0}+n_{0,1}} \quad \text{and} \quad \widehat{p}_{1,1} = \frac{n_{1,1}}{n_{1,0}+n_{1,1}} $$from Utils import makeFreq
transitions_data = np.stack([all_daysdata[:-1],all_daysdata[1:]])
transitions_data[:,200:210]
transition_counts = makeFreq(transitions_data)
transition_counts
n_00 = transition_counts[0,-1]
n_01 = transition_counts[1,-1]
n_10 = transition_counts[2,-1]
n_11 = transition_counts[3,-1]
n_00, n_01, n_10, n_11
Make a function to make a transition counts matrix from any list of 0/1 tuples passed in.
Make a function to turn transitions counts into a matrix of values for:
$$\widehat{\mathbf{P}}=\begin{bmatrix} \hat{p}_{0,0} & \hat{p}_{0,1}\\ \hat{p}_{1,0} & \hat{p}_{1,1}\end{bmatrix}.$$def estimateMatrix(n_00,n_01,n_10,n_11):
p00 = n_00/(n_00+n_01)
p11 = n_11/(n_11+n_10)
p10 = 1-p11
p01 = 1-p00
return np.matrix([[p00,p01],[p10,p11]])
Look at this for all the data:
estimateMatrix(n_00,n_01,n_10,n_11)
evals,evecs = np.linalg.eig(estimateMatrix(n_00,n_01,n_10,n_11).T)
# During the lecture I forgot to transpose the transition matrix above
# which I should have due to the computation I did on the board
evals,evecs
evecs[:,0]/np.sum(evecs[:,0])
YouTry¶
Consider the Markov chain describing the mode of transport used by a lazy professor. He has only two modes of transport, namely Walk or Drive. Label Walk by $0$ and Drive by $1$. If he walks today then he will definitely drive tomorrow. But, if he drives today then he flips a fair coin to decide whether he will Walk or Drive tomorrow. His decision to get to work is the same on each day. In the cells below try to:
- Find the flow diagram
- Find and assign the transition probability matrix for this Markov chain
- Find the probability that he will drive on the $n$-th day given he will walk today (day $0$)
- What is the steady state probability vector for this chain?
Also do by hand!
<br> <br > <br> <br >