We have seen the probabilistic viewpoint of machine learning, by going from the Likelihood to the so called loss funcntion. Finding the MLE is finding the minima in the loss function.
Traditionally however the machine learning started in principle with a single algorithm called the perceptron algorithm. The ideas come from computer science and as such the focus and terminology is different, but let us stick to the terminology used in the book "Foundations of Data Science" Chap 5.
Let us say that we are trying to device a decision rule based on input data being in $\mathbb{R}^d$, it could be binary or other. This input could be for instance the words being used in an email, where we have some form of dictionary where each word is represented by a dimension. The simplest form of decision problem is that of a binary decision, like in the case of logistic regression (the decision could be the most likely output). A commonly chosen example is that of email spam classification.
Goal: find a "simple" rule that performs well on training data
The perceptron algorithm¶
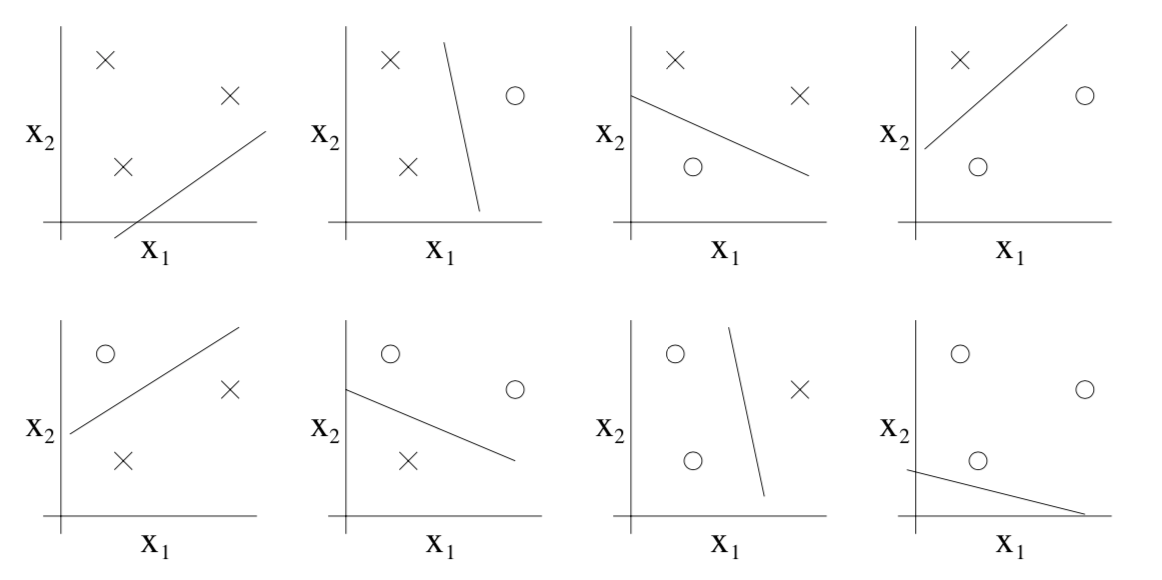
The perceptron algorithm tries to find a linear separator, i.e. a plane in $\mathbb{R}$ that separates the two classes. The task is thus to find $w$ and $t$ such that for the training data $S$, the data consists of pairs $(x_i,l_i)$ the $x_i$ represents our features and the $l_i$ our labels or target.
$$
\begin{aligned}
w \cdot x_i > t \quad \text{for each $x_i$ labeled $+1$} \\
w \cdot x_i < t \quad \text{for each $x_i$ labeled $-1$}
\end{aligned}
$$
Adding a new coordinate to our space allows us to consider $\hat x_i = (x_i,1)$ and $\hat w = (w,t)$, this allows us to rewrite the inequalities above as
$$
(\hat w \cdot \hat x_i) l_i > 0.
$$
The algorithm¶
- $w = 0$
- while there exists $x_i$ with $x_i l_i \cdot w \leq 0$, update $w := w+x_il_i$