Markov chain, named after Andrey Markov, is a mathematical model for a possibly dependent sequence of random variables.

Intuitively, a Markov Chain is a system which "jumps" among several states, with the next state depending (probabilistically) only on the current state. A useful heuristic is that of a frog jumping among several lily-pads, where the frog's memory is short enough that it doesn't remember what lily-pad it was last on, and so its next jump can only be influenced by where it is now.
Formally, the Markov property states that the conditional probability distribution for the system at the next step (and in fact at all future steps) given its current state depends only on the current state of the system, and not additionally on the state of the system at previous steps:
$$P(X_{n+1} \ | \, X_1,X_2,\dots,X_n) = P(X_{n+1}|X_n). \,$$Since the system changes randomly, it is generally impossible to predict the exact state of the system in the future. However, the statistical and probailistic properties of the system's future can be predicted. In many applications it is these statistical properties that are important.
Formal definition and terms¶
A Markov chain is a sequence of random variables $X_1, X_2, X_3, \ldots$ with the Markov property, namely that, given the present state, the future and past states are independent. Formally,
$$P(X_{n+1}=x \ | \ X_1=x_1, X_2=x_2 \ldots, X_n=x_n) = P(X_{n+1}=x|X_n=x_n).\,$$The possible values of $X_i$ or the set of all states of the system form a countable set $\mathbb{X}$ called the state space of the chain.
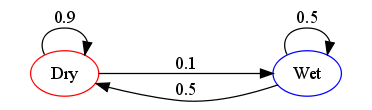
The changes of state of the system are called transitions, and the probabilities associated with various state-changes are called transition probabilities.
Markov chains are often depicted by a weighted directed graph, where the edges are labeled by the probabilities of going from one state to the other states. This is called the flow diagram or transition probability diagram. The transition probability matrix $\mathbf{P}$ encodes the probabilities associated with state-changes or "jumps" from one state to another in the state-space $\mathbb{X}$. If $\mathbb{X}$ is labelled by $\{0,1,2,\ldots\}$ then the $i,j$-th entry in the matrix $\mathbf{P}$ corresponds to the probability of going from state $i$ to state $j$ in one time-step.
$$\mathbf{P} = \begin{bmatrix} p_{0,0} & p_{0,1} & p_{0,2} & \ldots \\ p_{1,0} & p_{1,1} & p_{1,2} & \ldots \\ p_{2,0} & p_{2,1} & p_{2,2} & \ldots \\ \vdots & \vdots & \vdots & \ddots \end{bmatrix}$$The state of the system at the $n$-th time step is described by a state probability vector $$\mathbf{p}^{(n)} = \left( \mathbf{p}^{(n)}_0, \mathbf{p}^{(n)}_1, \mathbf{p}^{(n)}_2,\ldots \right)$$ Thus, $\mathbf{p}^{(n)}_i$ is the probability you will find the Markov chain at state $i \in \mathbb{X}$ at time-step $n$ and $\mathbf{p}^{(0)}_i$ is called the initial probability vector at the convenient initial time $0$.
The state space $\mathbb{X}$ and transition probability matrix $\mathbf{P}$ completely characterizes a Markov chain.