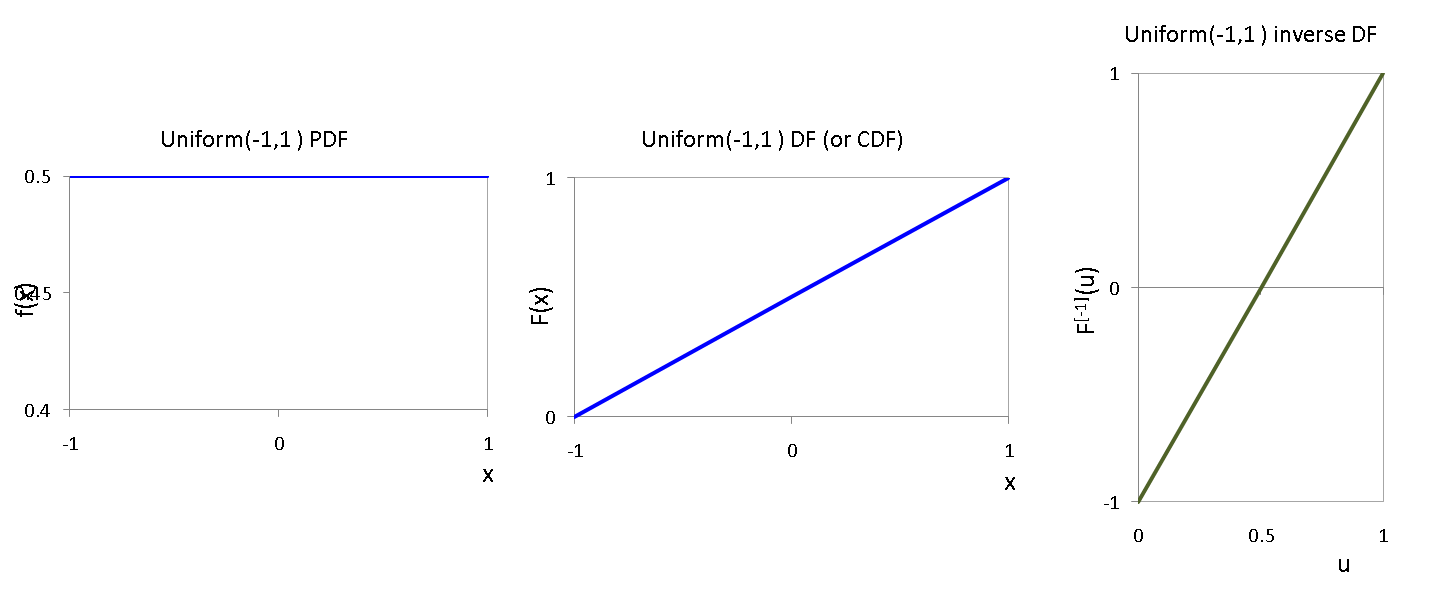
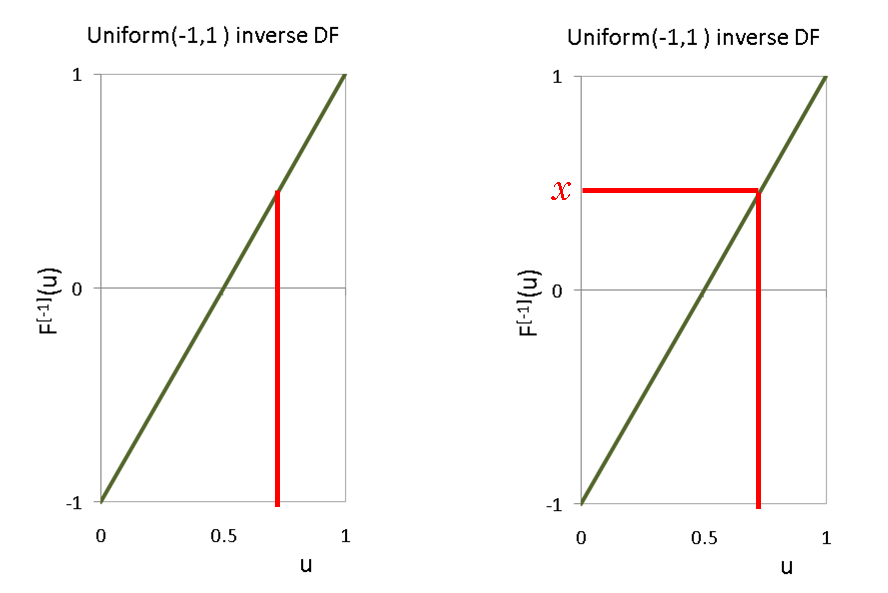
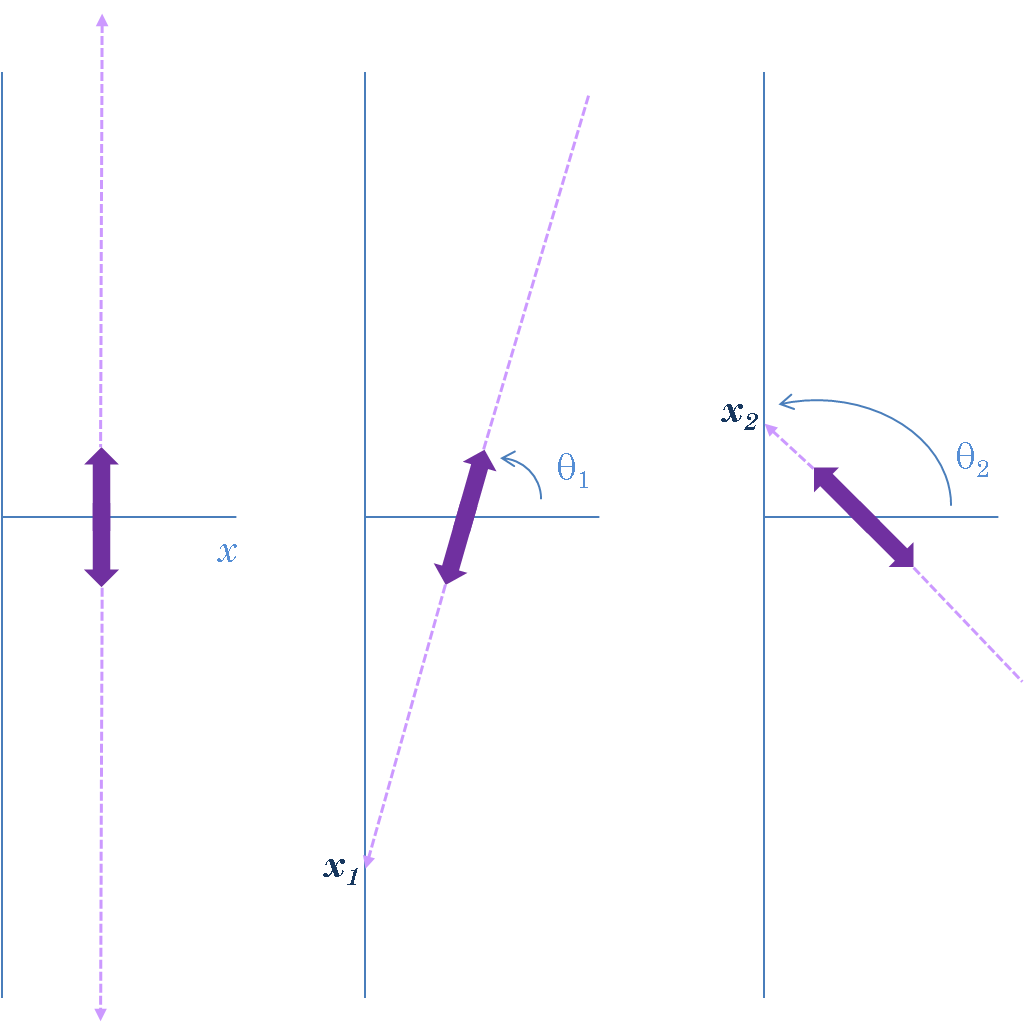
[0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 29, 21, 0, 0, 4, 3, 0, 0, 0, 8, 0, 0, 0, 4, 7, 0, 32, 38, 1, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 1, 8, 0, 0, 0, 0, 0, 0, 0, 0, 15, 9, 11, 10, 0, 0, 13, 0, 0, 0, 0, 1, 5, 0, 0, 0, 0, 0, 17, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 5, 0, 42, 12, 12]
[0, 4, 16, 23, 1, 2, 16, 17, 10, 0, 2, 6, 0, 6, 3, 3, 1, 1, 18, 22, 1, 17, 3, 4, 24, 0, 2, 9, 8, 3, 3, 14, 16, 7, 19, 38, 5, 10, 9, 4, 5, 18, 2, 7, 19, 1, 24, 14, 12, 9, 6, 3, 3, 19, 29, 2, 3, 15, 6, 20, 1, 2, 8, 14, 3, 14, 6, 4, 19, 0, 10, 2, 4, 3, 10, 6, 3, 9, 13, 9, 20, 0, 1, 7, 22, 6, 2, 0, 2, 11, 13, 13, 12, 1, 15, 2, 13, 14, 35, 8]
[0.0460013500020229, 4.46853364965950, 16.3458438888944, 23.5466240445700, 1.89784664949937, 2.38162182407556, 16.4765518467873, 20.4722960331639, 7.38369263028937, 0.0691371236991783, 2.60803315542263, 6.47873812759680, 0.812534745415746, 6.27925136885093, 3.18053215099416, 3.79957425916417, 1.73796705407665, 30.2739087104418, 10.4215644773435, 1.32846249224355, 1.07825838297442, 21.4629044648545, 2.34859051540700, 1.47387242251340, 24.0133527232019, 0.503472678229878, 10.5513302729022, 1.65976774220080, 8.42758360570952, 3.03998696950365, 7.65979116002352, 17.4397211384731, 9.60519945070885, 39.5035163669874, 25.2640355505816, 1.72656895023283, 11.9983168710317, 3.75834445594812, 9.06893249764261, 4.62566239958095, 5.76003710667431, 18.2600202585963, 2.64278686942174, 7.56904759855853, 19.3333412380615, 1.61381528984074, 30.2463921733627, 8.71171543271941, 12.9092008657373, 9.83962761949938, 6.69432550334831, 4.93295202372363, 10.1091551778993, 11.3709710592170, 29.6395852475420, 2.11692708479339, 3.88138096846034, 15.1803552726759, 6.31316998108956, 20.0964474896577, 1.49397738691626, 17.0792453180813, 2.95044442518636, 16.0157150824620, 2.95160169138103, 4.47482513485162, 6.53097919896797, 17.8095339959281, 6.21403724631756, 0.401048957748739, 10.9180355386613, 2.50371109535955, 5.51232834067426, 7.21314159334563, 5.05013789677719, 6.18146754796122, 3.21459272389129, 9.92142766721676, 13.1321171652937, 26.8275239335769, 3.13583160307068, 0.499250356673742, 1.24928796937012, 9.03969072320646, 20.7705710898953, 6.04512644002478, 2.56218711961558, 0.602994993742728, 2.78381803185431, 11.9339815720172, 13.7053668866893, 13.6256336794782, 12.1599432867189, 1.11216355232017, 21.7646932005282, 1.09572212822393, 8.03202624598593, 56.5150815923828, 5.01861374006982, 8.69846371308286]