Random Variables¶
A random variable is a mapping from the sample space $\Omega$ to the set of real numbers $\mathbb{R}$. In other words, it is a numerical value determined by the outcome of the experiment. (Actually, this is a real-valued random variable and one can have random variables taking values in other sets).
This is not as complicated as it sounds: let's look at a simple example:
Example¶
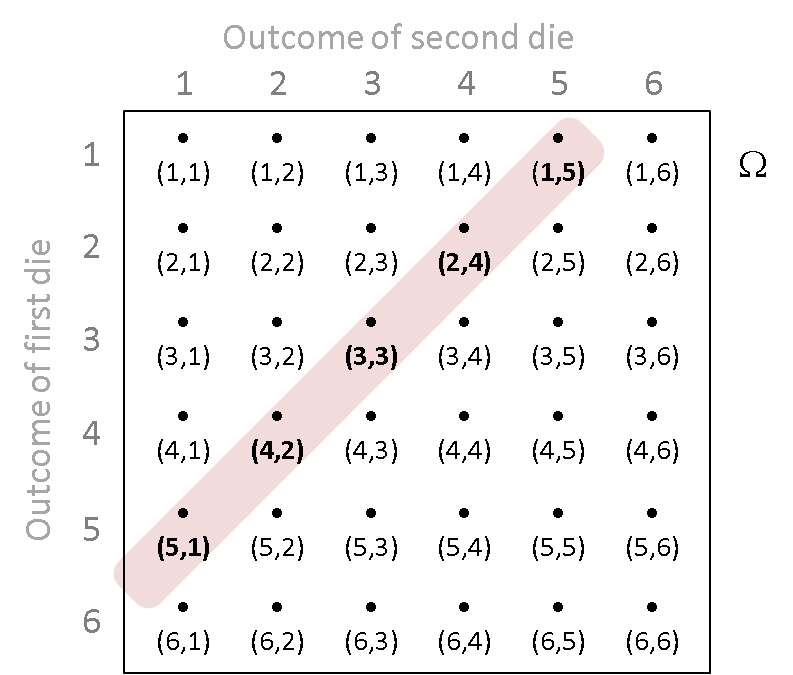
Roll two fair dice.¶
The sample space is the set of 36 ordered pairs $\Omega = \{(1,1), (1,2), \dots, (2,1), (2,2), \ldots, (1,6), \ldots, (6,6)\}$
Let random variable $X$ be the sum of the two numbers that appear, $X : \Omega \rightarrow \mathbb{R}$.
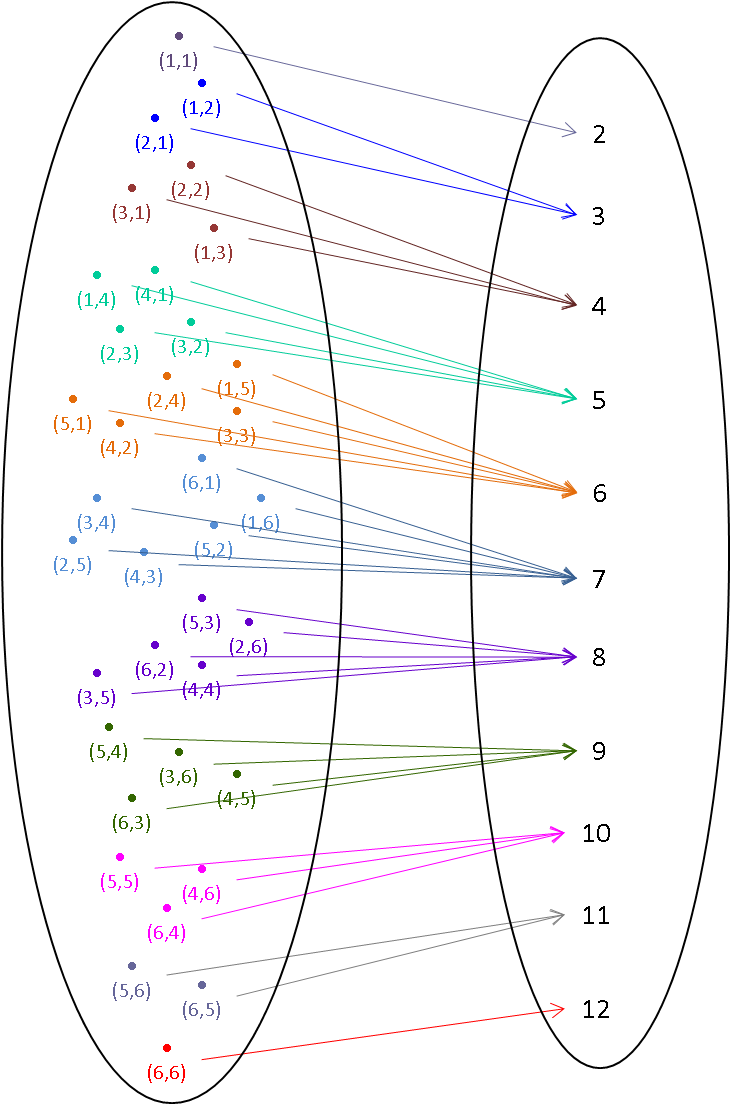
For example, $X\left(\{(6,6)\}\right) = 12$
$P(X=12) = P\left(\{(6,6)\}\right)$
And, $X\left( \{ (3,2) \}\right) = 5$
Formal definition of a random variable
Let $\left(\Omega, \mathcal{F}, P \right)$ be some probability triple. Then a random variable, say $X$, is a function from the sample space $\Omega$ to the set of real numbers $\mathbb{R}$
$$X: \Omega \rightarrow \mathbb{R}$$
such that for every number $x$ in $\mathbb{R}$, the inverse image of the half-open interval $(-\infty, x]$ is an element of the collection of events $\mathcal{F}$, i.e.,
for every number $x$ in $\mathbb{R}$,
$$X^{[-1]}\left( (-\infty, x] \right) := \{\omega: X(\omega) \le x\} \in \mathcal{F}$$
Discrete random variable¶
A random variable is said to be discrete when it can take a countable sequence of values (a finite set is countable). The three examples below are discrete random variables.
Probability of a random variable¶
Finally, we assign probability to a random variable $X$ as follows:
$$P(X \le x) = P \left( X^{[-1]}\left( (-\infty, x] \right) \right) := P\left( \{ \omega: X(\omega) \le x \} \right)$$
Distribution Function¶
The distribution function (DF) or cumulative distribution function (CDF) of any RV $X$, denoted by $F$ is:
$$F(x) := P(X \leq x) = P\left( \{ \omega: X(\omega) \leq x \} \right) \mbox{, for any } x \in \mathbb{R}$$
Example - Sum of Two Dice¶
In our example above (tossing two die and taking $X$ as the sum of the numbers shown) we said that $X\left((3,2)\right) = 5$, but (3,2) is not the only outcome that $X$ maps to 5: $X^{[-1]}\left(5\right) = \{(1,4), (2,3), (3,2), (4,1)\}$
$$
\begin{array}{lcl} P(X=5) & = & P\left(\{\omega: X(\omega) = 5\}\right)\\ & = & P\left(X^{[-1]}\left(5\right)\right)\\ & = & P(\{(1,4), (2,3), (3,2), (4,1)\})
\end{array}
$$
Example - Pick a Fruit at Random¶
Remember our "well-mixed" fruit bowl containing 3 apples, 2 oranges, 1 lemon? If our experiment is to take a piece of fruit from the bowl and the outcome is the kind of fruit we take, then we saw that $\Omega = \{\mbox{apple}, \mbox{orange}, \mbox{lemon}\}$.
Define a random variable $Y$ to give each kind of fruit a numerical value: $Y(\mbox{apple}) = 1$, $Y(\mbox{orange}) = 0$, $Y(\mbox{lemon}) = 0$.
Example - Flip Until Heads¶
Flip a fair coin until a 'H' appears. Let $X$ be the number of times we have to flip the coin until the first 'H'.
$\Omega = \{\mbox{H}, \mbox{TH}, \mbox{TTH}, \ldots, \mbox{TTTTTTTTTH}, \ldots \}$
$X(\mbox{H}) = 0$, $X(\mbox{TH}) = 1$, $X(\mbox{TTH}) = 2$, $\ldots$
You try at home¶
Consider the example above of 'Pick a Fruit at Random'. We defined a random variable $Y$ there as $Y(\mbox{apple}) = 1$, $Y(\mbox{orange}) = 0$, $Y(\mbox{lemon}) = 0$. Using step by step arguments as done in the example of 'Sum of Two Dice' above, find the following probabilities for our random variable $Y$:
$$
\begin{array}{lcl}
P(Y=0) & = & P\left(\{\omega: Y(\omega) = \quad \}\right)\\ & = & P\left(Y^{[-1]} \left( \quad \right)\right)\\ &= & P(\{\quad , \quad \})
\end{array}
$$
Watch the Khan Academy movie about random variables
When we introduced the subject of probability, we said that many famous people had become interested in it from the point of view of gambling. Games of dice are one of the earliest forms of gambling (probably deriving from an even earlier game which involved throwing animal 'ankle' bones or astragali). Galileo was one of those who wrote about dice, including an important piece which explained what many experienced gamblers had sensed but had not been able to formalise - the difference between the probability of throwing a 9 and the probability of throwing a 10 with two dice. You should be able to see why this is from our map above. If you are interested you can read a translation (Galileo wrote in Latin) of Galileo's Sorpa le Scoperte Dei Dadi. This is also printed in a nice book, Games, Gods and Gambling by F.N. David (originally published 1962, newer editions now available).
Implementing a Random Variable¶
We have made our own random variable map object in Sage called RV. As with the Sage probability maps we looked at last week, it is based on a map or dictionary. We specify the sample the samplespace and probabilities and the random variable map, MapX, from the samplespace to the values taken by the random variable $X$).