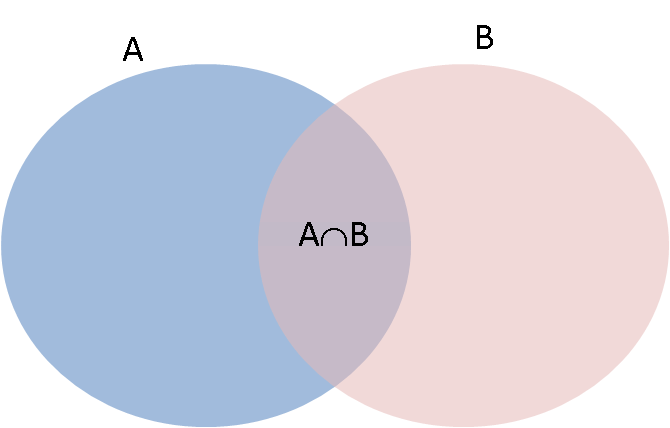
Maps and Functions¶
In the last notebook we understood sets. We can now understand functions which can be thought intuitively as a "black box" named $f$ that takes an input $x$ and returns an output $y=f(x)$.
 |
 |
|---|
More formally, a function is a relation between a set of inputs and a set of permissible outputs with the property that each input is related to exactly one output.
The two sets for inputs and outputs are traditionally called domain and range or codomain, respectively.
The map or function associates each element in the domain with exactly one element in the range.
So, more than one distinct element in the domain can be associated with the same element in the range, and not every element in the range needs to be mapped (i.e, not everything in the range needs to have something in the domain associated with it).
Here is a map for some family relationships:
- $Raaz$ has two daughters named $Anu$ and $Ashu$,
- $Jenny$ has a sister called $Cathy$ and the father of $Jenny$ and $Cathy$ is $Jonathan$, and
- $Fred$ is a man who has no daughter.
We can map these daughters to their fathers with the $FindFathersMap$ shown below: The daughters are in the domain and the fathers are in the range made up of men. Each daughter maps to a father (there is no immaculate conceptions here!). More than one daughter can map to the same father (some fathers have more daughters!). But there can be men in the range who are not fathers (this is also natural, may be they only have sons or have no children at all).
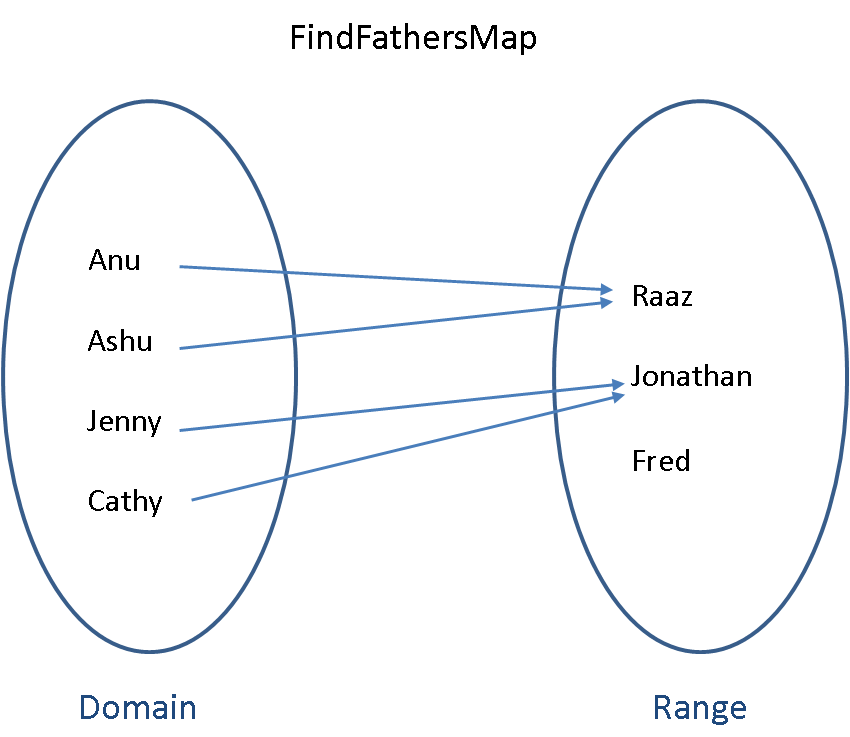
The notation for this mapping would be:
$$FindFathersMap: Daughters \rightarrow Men$$The domain is the set:
$$Daughters = \{Anu, Ashu, Jenny, Cathy\}$$and the range or codomain is the set:
$$Men = \{Raaz, Jonathan, Fred\}.$$The element in the range that an element in the domain maps to is called the image of that domain element. Sometimes range is used interchangably with image, and sometimes it refers to the codomain, depending on where you read. This is a good thing to keep in mind. For example, $Raaz$ is the image of $Anu$ in the $FindFathersMap$. The notation for this is:
$$FindFathersMap(Anu) = Raaz \ .$$Note that what we have just written is a function, just like the more familiar format of
$$f(x) = y \ .$$In computer science lingo each element in the domain is called a key and the images in the range are called values. The map or function associates each key with a value.
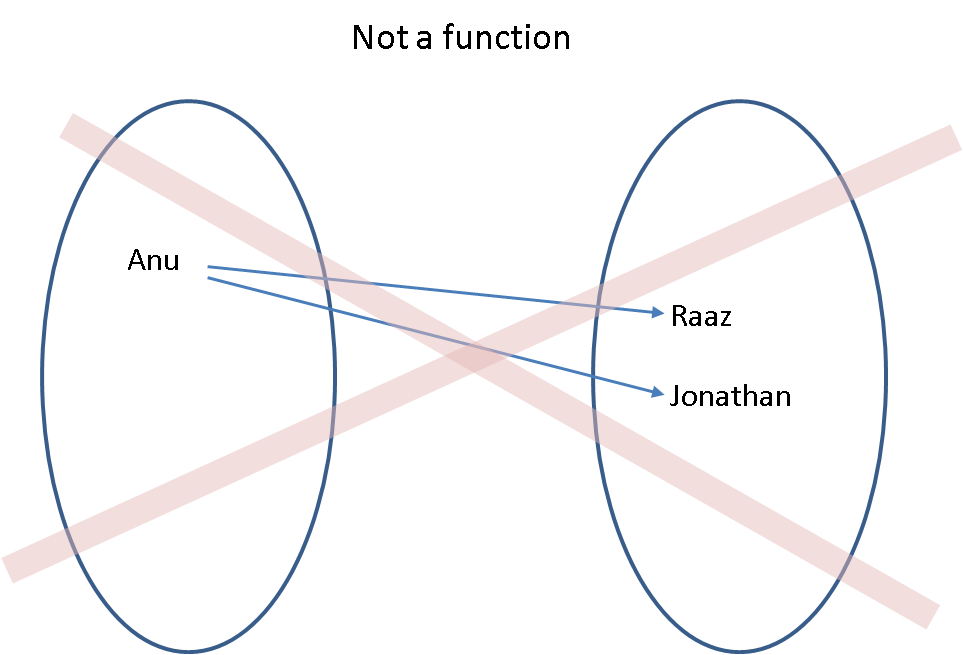
The keys for the map are unique since the domain is a set, i.e., a collection of distinct elements. Lots of keys can map to the same image value ($Jenny$ and $Cathy$ have the same father, $Anu$ and $Ashu$ have the same father), but the idea is that we can uniquely identify the value we want if we know the key. This means that we can't have multiple identical keys. This makes sense when you look at how the map works. We use the map to find values from the key, as we did when we found $Anu$'s father above. If we had more than one $Anu$ in the set of keys, we could not uniquely identify the value that maps to the key $Anu$.
We do not allow maps (functions) where one element in the domain maps to more than one element in the range. In computer science lingo, each key can have only one value associated with it.
Formalising this, a function $f: \mathbb{X} \rightarrow \mathbb{Y}$ that maps each element $x \in \mathbb{X}$ to eaxctly one element $f(x) \in \mathbb{Y}$ is equivalent to the corresponding set of ordered pairs: $$\left\{(x, f(x)): x \in \mathbb{X}, f(x) \in \mathbb{Y}\right\} \ .$$
Here, $\left(x, f(x)\right)$ is an ordered pair (the familiar key-value pair in computer science).
The pre-image or inverse image of a function $f: \mathbb{X} \rightarrow \mathbb{Y}$ is $f^{[-1]}$.
The inverse image takes subsets in $\mathbb{Y}$ and returns subsets of $\mathbb{X}$.
The pre-image or inverse image of $y$ is $f^{[-1]}(y) = \left\{x \in \mathbb{X} : f(x) = y \right\} \subset \mathbb{X}$.
More generally, for any $B \subset \mathbb{Y}$:
$f^{[-1]}(B) = \{x \in \mathbb{X}: f(x) \in B \}$
For example, for our FindFathersMap,
- $FindFathersMap^{[-1]}(Raaz) = \{Anu, Ashu\}$ and
- $FindFathersMap^{[-1]}(Jonathan) = \{Jenny, Cathy\}$.
Now lets take a more mathematical looking function $f(x) = x^2$.
Version 1 of this function is going to have a finite domain (only five elements).
The domain is the set $\{-2, -1, 0, 1, 2\}$ and the range is the set $\{0, 1, 2, 3, 4\}$.
The mapping for version 1 is $$f(x) = x^2\,:\,\{-2, -1, 0, 1, 2\} \rightarrow \{0, 1, 2, 3, 4\} \ .$$
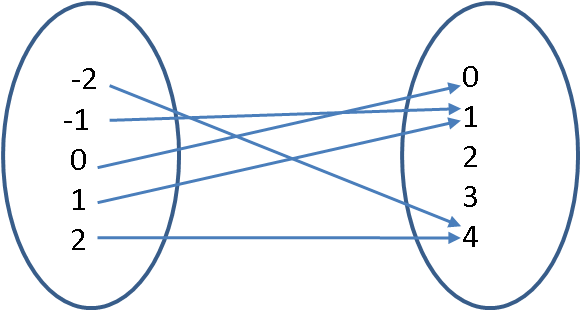
We can also represent this mapping as the set of ordered pairs $\{(-2,4), (-1,1), (0,0), (1,1), (2,4)\}$.
Note that the values 2 and 3 in the range have no pre-image in the domain. This is okay because not every element in the range needs to be mapped.
Having a domain with only five elements in it is a bit restrictive: how about an infinite domain?
Version 2
$$f(x) = x^2\,:\,\{\ldots, -2, -1, 0, 1, 2, \ldots\} \rightarrow \{0, 1, 2, 3, 4, \ldots\}$$
As ordered pairs, we now have $\{\ldots, (-2,4), (-1,1), (0,0), (1,1), (2,4), \ldots\}$, but it is impossible to write them all down since there are infinitely many elements in the domain.
What if we wanted to use the function for the whole of $\mathbb{R}$, the real line?
Version 3
$$f(x) = x^2 : \mathbb{R} \rightarrow \mathbb{R} \ . $$